Case Study – Stitch Lineage
Amperity is the leading customer data platform (CDP) provider that helps companies put data to work to improve marketing performance, build long-term customer loyalty and drive revenue. Amperity is used by many of the world’s most beloved brands, such as Alaska Airlines, Endeavour Drinks, Kendra Scott, Lucky Brand, Planet Fitness, Seattle Sounders FC, Under Armour and Wyndham Hotels & Resorts
Stitch Lineage - Intro
Stitch uses algorithms to evaluate massive volumes of data to discover the hidden connections in customer records that identify unique individuals. Stitch outputs a unified collection of data that assigns a unique identifier to each unique individual that is discovered within customer records.Identity resolution is a critical step in understanding who your customers are. Stitch is the component within Amperity that performs identity resolution by comparing all of your customer data, identifying unifying groups of customer records, and then identifying unique customer profiles that represent each of your unique, individual customers.
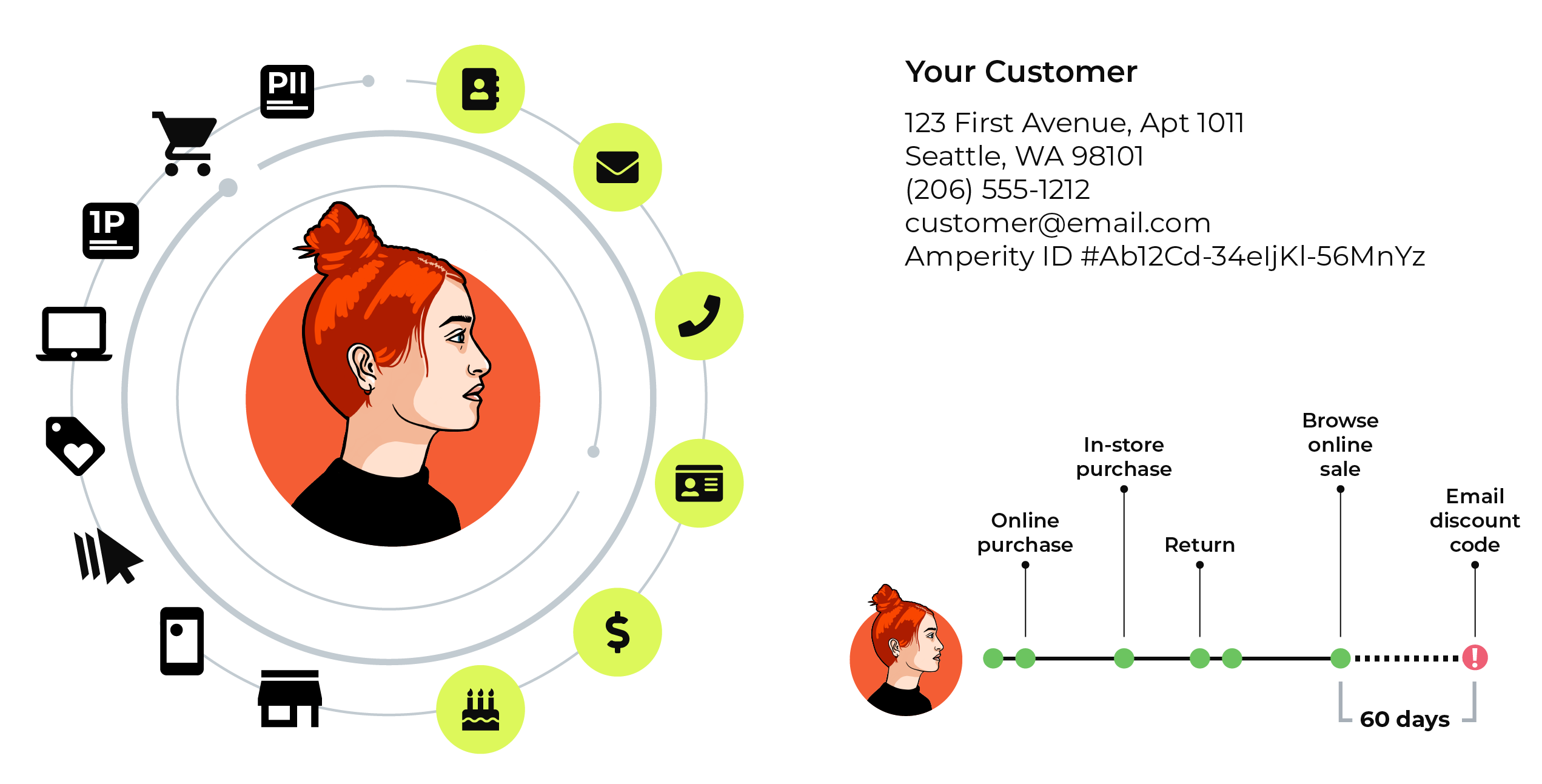
Amperity uses a series of innovations to ensure that identity resolution against your customer data is accurate and that the output of the Stitch process represents a true unified view of customers. Stitch relies on the following semantic tags to be applied to customer records:
- given-name (first name) and surname (last name). In some cases, a full-name is inferred (if not available).
- Other important profile details, such as birthdate, email, and phone.
- The address, address2, city, state, and postal tags are combined to represent a complete physical address.
- Other location details, such as country and company.
- Additional profile details, when available, such as gender, generational-suffix (Jr., Sr., III, etc.), and title.
Pain Points
To understand the pain points, it is important to understand how the identity resolution works at a high level. For example, a customer has data sources for online transactions, in-store transactions, loyalty programs, clickstream data for a mobile application, and so on.
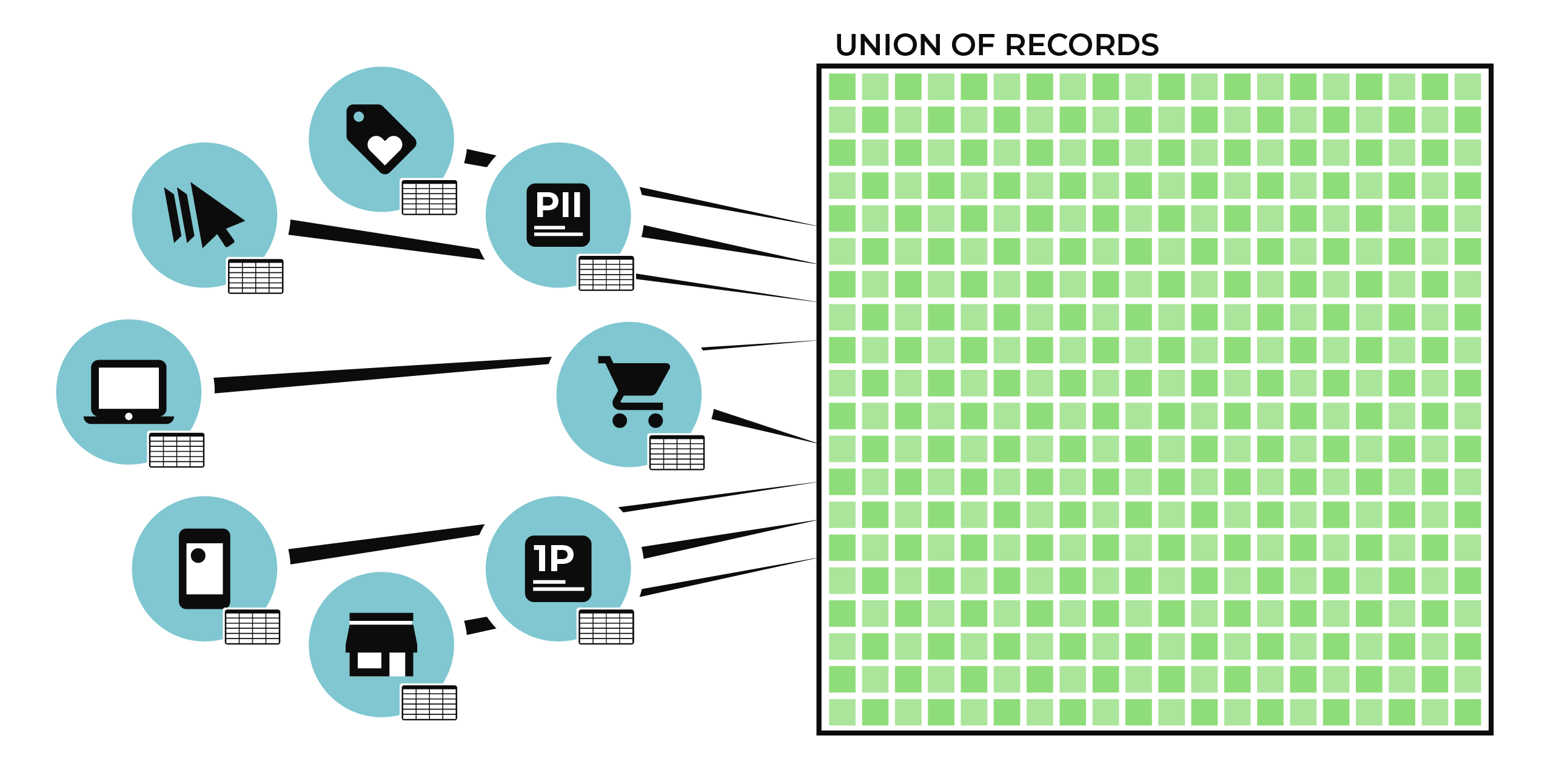
Semantic tags are applied to all of these data sources consistently across all data sources. Every email address, physical address, phone number, first and last name is associated to profile semantics. Every order, item, purchase amount, discount amount, return, is associated to transaction semantics. Stitch will look at these different sources and compare these semantic tags and provide a score depending on the priority of the tags. It will provide a score pairing difference data sources with the same semantic tag.
Scoring are generally given a ranking of: Exact, Excellent, High, Moderate, and Weak. Here is an example:
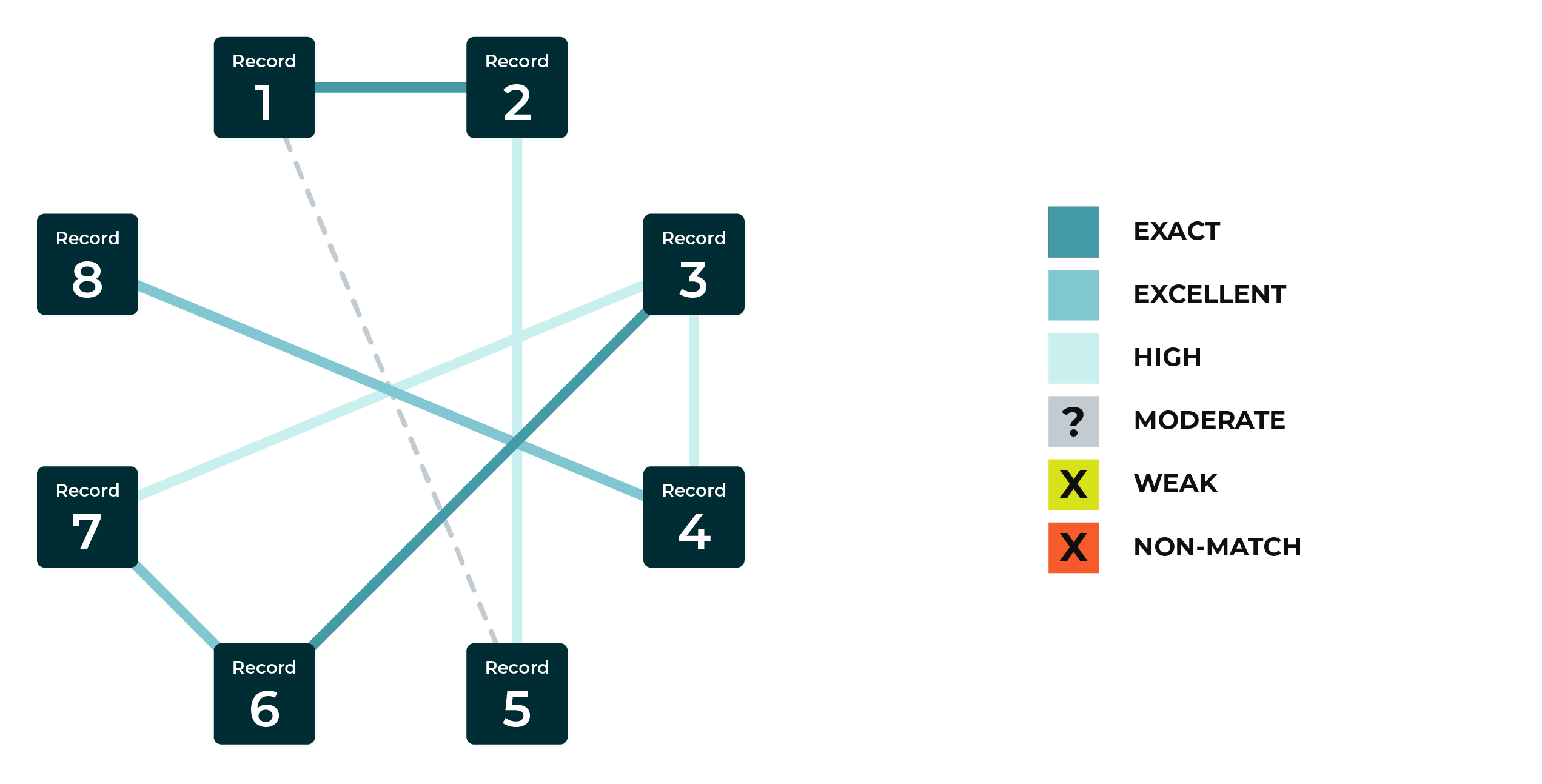
The results of Stitch based on the record matching are relayed back to the customer in a table with the scores. However, the customer is constantly reaching back out to Amperity to inquire about the scores between 1 or more records. This creates a huge amount work to the operators at Amperity where they need to manually research each of the records pairs. There is no elegant way to drill down into each of the records pairs without spending an enormous amount of time looking at the code itself. The number one requests from the operators during office hours, is the ability to drill down on a particular record pairing.
Solution
In building the prototypes and working with the lead product manager, we agreed upon the following high level requirements:
- Easily discoverable and accessible on the website
- Consistent UX/UI across the website
- Ability to display the detailed information while showing the record name and primary key
- Provide the detailed information on how the record matching was scored
- Provide a visual ranking for each of the semantic tags
- Ability to choose a different datasource and primary key to compare with the original record
We decided the entry point that makes the most sense is in the data explorer where the user can drill down for each of the pairs comparison. Using the term, "Explore Match" is a common term used by operators making it more discoverable:
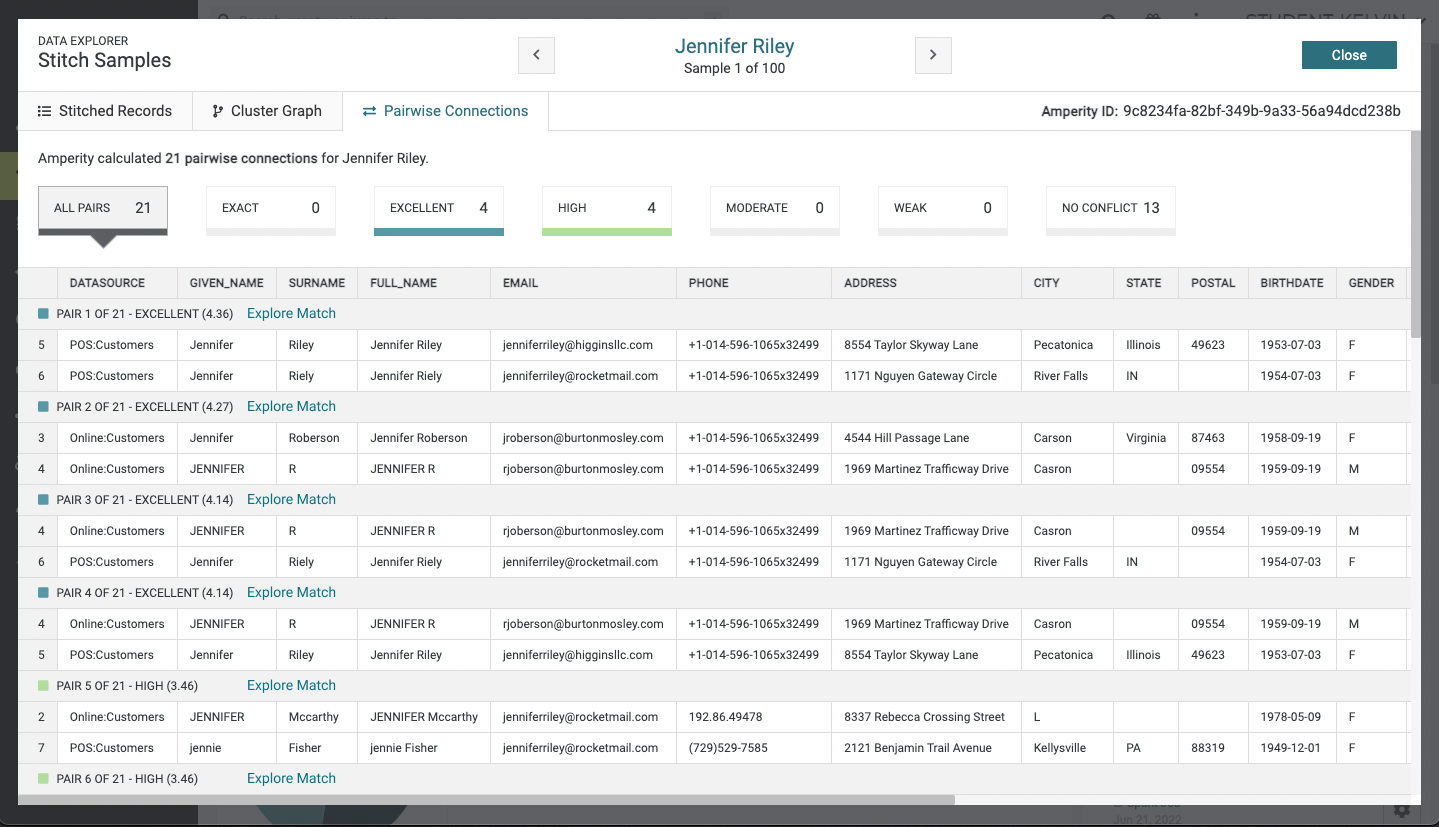
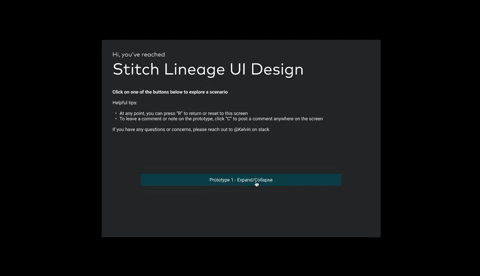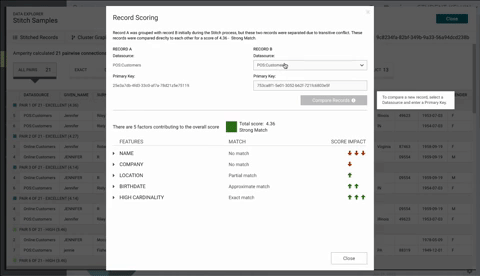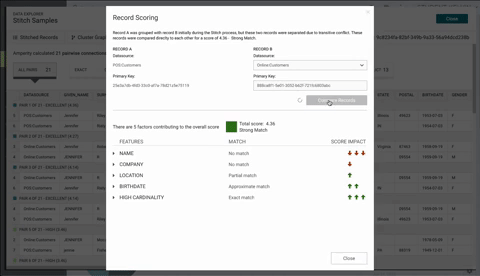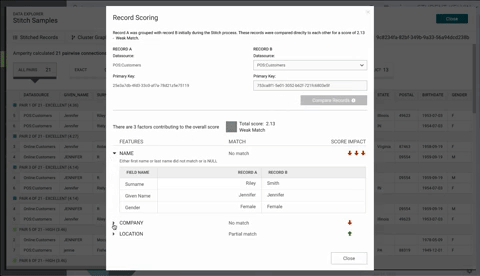
The first iteration of the design provided a top down design showing the explanation, record name & primary key in the header table, semantic tags, and then the overall score:
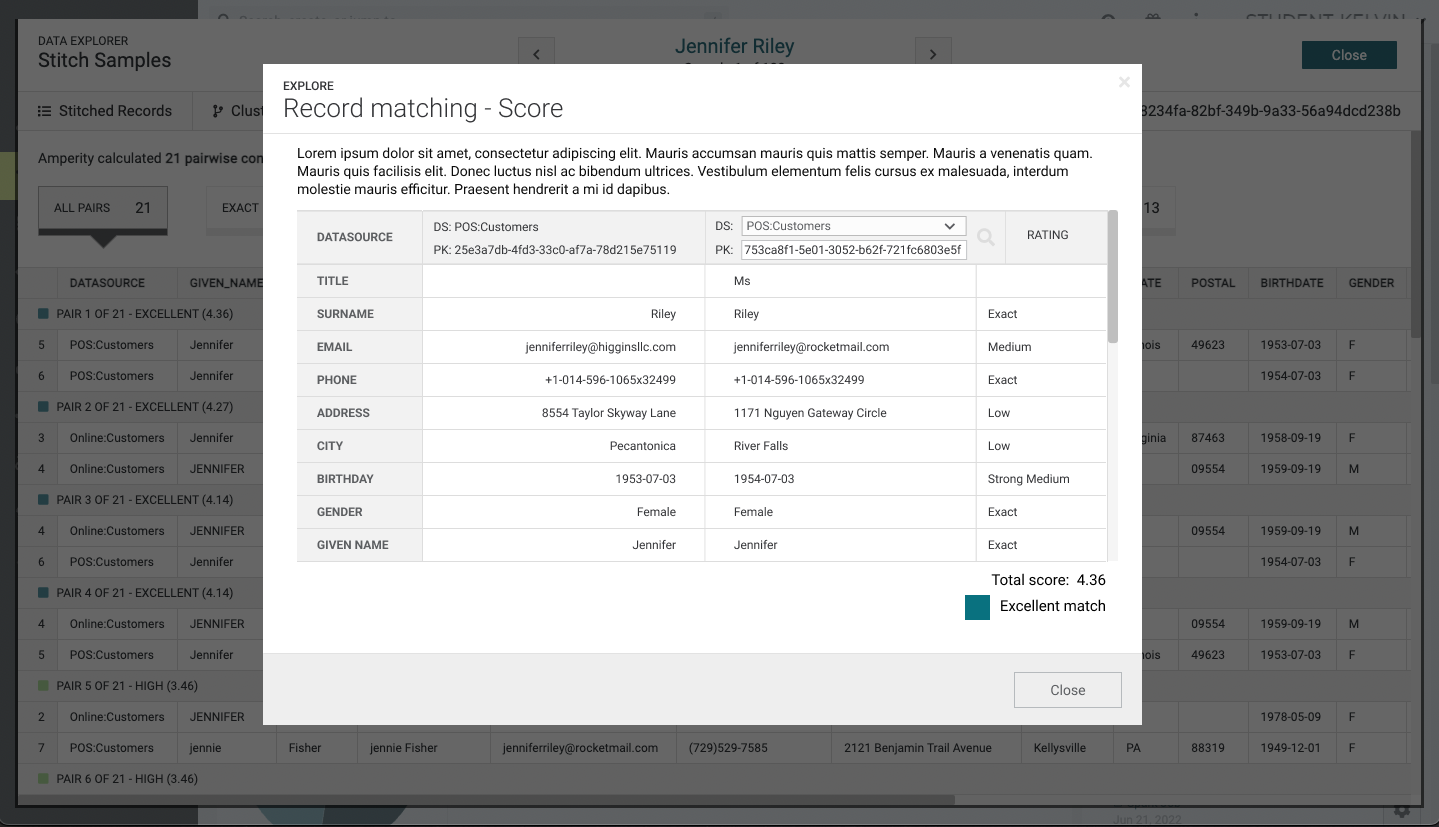
There are problems with this approach. First, introducing a drop down and an input field within a table header was non-standard and not used anywhere on the site. This introduces a new behavior that probably wasn't going to be used elsewhere and a new component would need to be created in the design system. Secondly, there were concerns showing the actual score at the bottom. This overall score should be more prominent. Also, if there were many semantic tags to display, a considerable amount of scrolling would be needed.
A better approach as shown below is move the record comparison to top, display the score in the center with, use collapsible carets to display more information for each of the semantic tags, and provide visual icons to display the score impact. One can argue the "Compre Records" button could be smaller to reduce white space at the top and table to display the record when expanded could be a different format to reduce vertical space. Unfortunately with the current design system, these component did not exist yet. That being said, I am personally pushed for new changes for the design system.
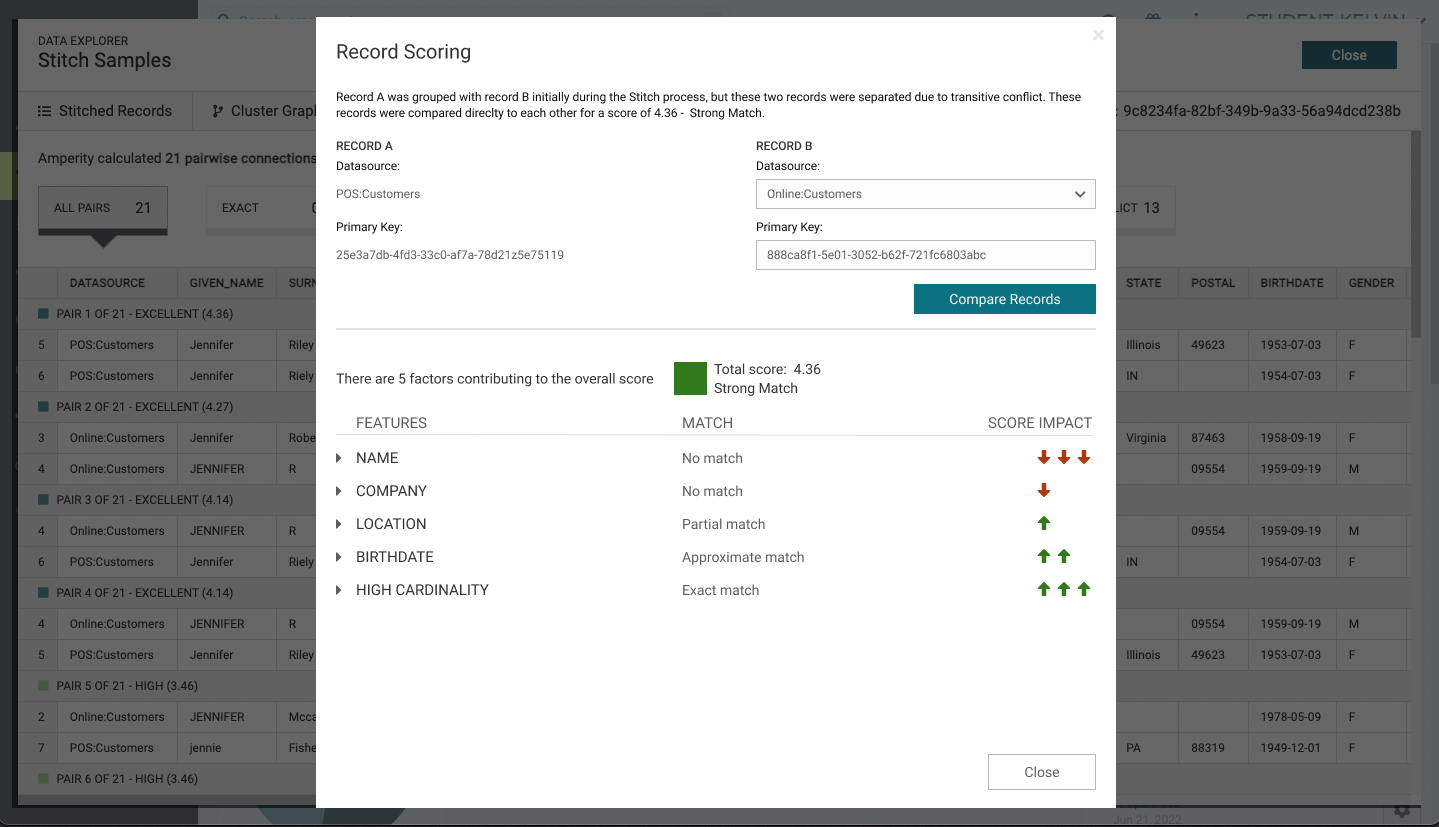
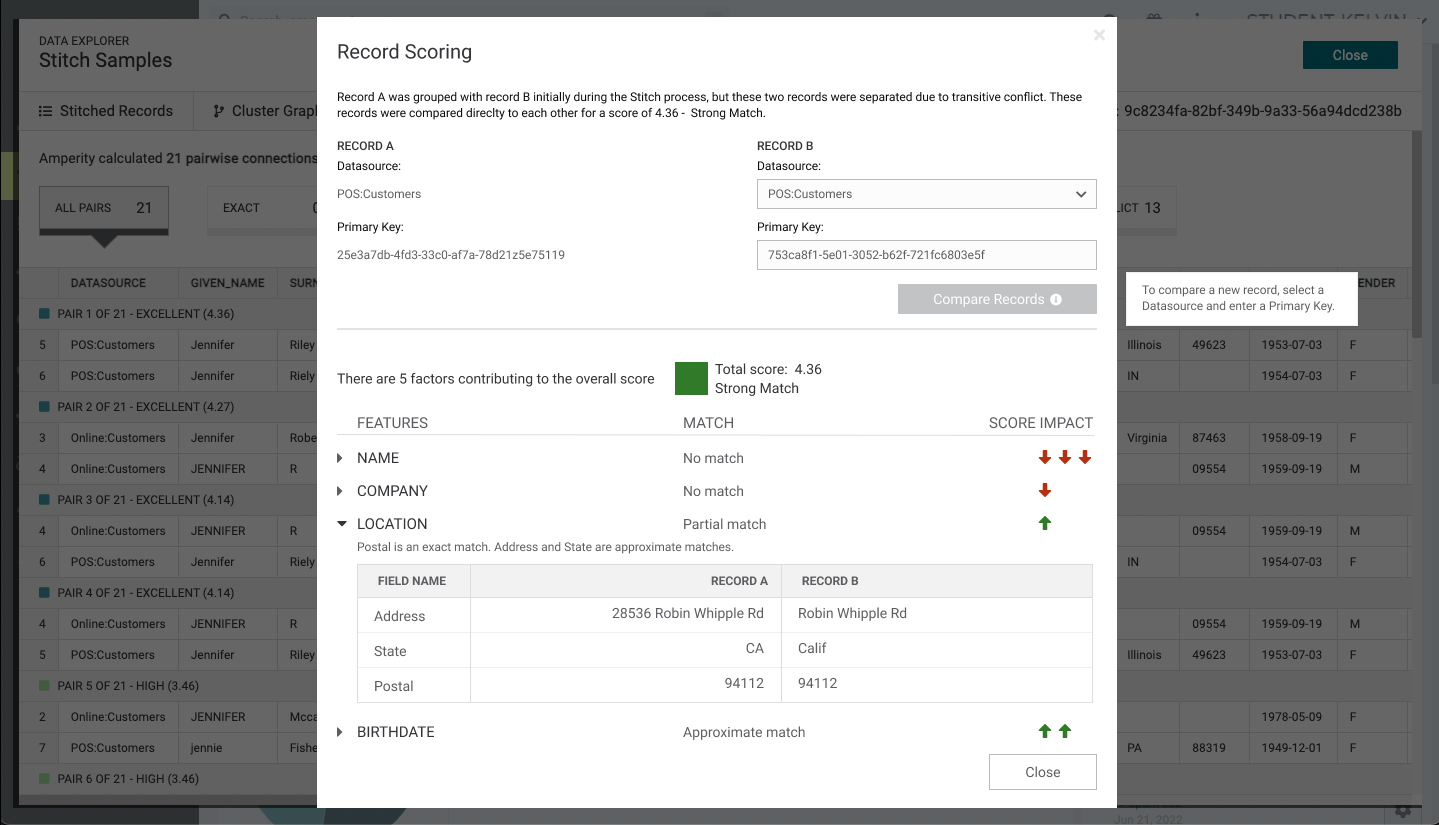
Summary
The Stitch process is the core of Amperity's identity resolution. The ability to drill down on the record matching score elevates the stitch process and allows the customer to be more informed and make better decisions based on the data. The design that was presented solves the pain point and meets the requirements needed to improve the overall Stitch experience.